













































CrawlX - Search Engine Scraper
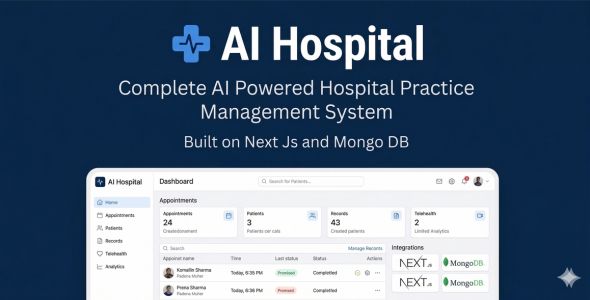
CrawlX – Search Engine Scraper Our CrawlX – Search Engine Scrape extracts high-value data — including keywords, business contact details, and Google Maps result

CrawlX – Search Engine Scraper
Our CrawlX – Search Engine Scrape extracts high-value data — including keywords, business contact details, and Google Maps results — quickly and accurately. It automates your data collection pipeline for analytics, lead generation, and custom applications.
Our Bing, Yahoo & DuckDuckGo Scrapers pull valuable data from each respective platform — contact info, keywords, and location-based links — streamlining collection for analytics, marketing, and integrations.
This tool lets you extract and download B2B data from multiple search engines, with built-in tools to send cold calls, WhatsApp messages, SMS, and emails — all from one place.
✅ Compatibility (newly added)
Supported Browsers:- Google Chrome 90+
- Mozilla Firefox 88+
- Microsoft Edge 90+
- Safari 14+
Operating System:
- Windows 10 / 11
- macOS 12 (Monterey) and above
- Ubuntu 20.04+ / Debian-based Linux
Server Requirements:
- NextJS or Node.js 16+
- MySQL 5.7+ / MariaDB 10.4+
- Minimum 1 GB RAM, 500 MB disk space
Frontend Stack:
- Bootstrap 4, jQuery 3.x, Font Awesome 5
What's Your Reaction?
 Like
0
Like
0
 Dislike
0
Dislike
0
 Love
0
Love
0
 Funny
0
Funny
0
 Angry
0
Angry
0
 Sad
0
Sad
0
 Wow
0
Wow
0